
Python(openpyxl)で、Excelの重複データを削除・抽出・色付けする方法を紹介します。
ぜひ、お試しください。
Excelの重複データを削除
以下のコードを実行すると、ダブリをチェックして該当行を削除します。
import openpyxl
wb = openpyxl.load_workbook('C:/Users/xxx/Desktop/test/test.xlsx')
ws = wb['Sheet1']
#配列宣言
Chiiki = []
#先頭行からループ
for Q in range(ws.max_row + 1):
if Q == 0:
continue
#セル値を変数へ格納
list = ws.cell(Q, 1).value
#セル値の行番号を取得
list_Num = Q
#最終行から逆ループ
for i in reversed(range(ws.max_row + 1)):
if i == 0:
break
#セル値とlistが一緒だったら
if ws.cell(i, 1).value == list:
#同じ行同士の比較はしない
if i == Q:
continue
else:
#行削除
ws.delete_rows(i)
#別名で保存
wb.save('C:/Users/xxx/Desktop/test/test重複削除.xlsx')
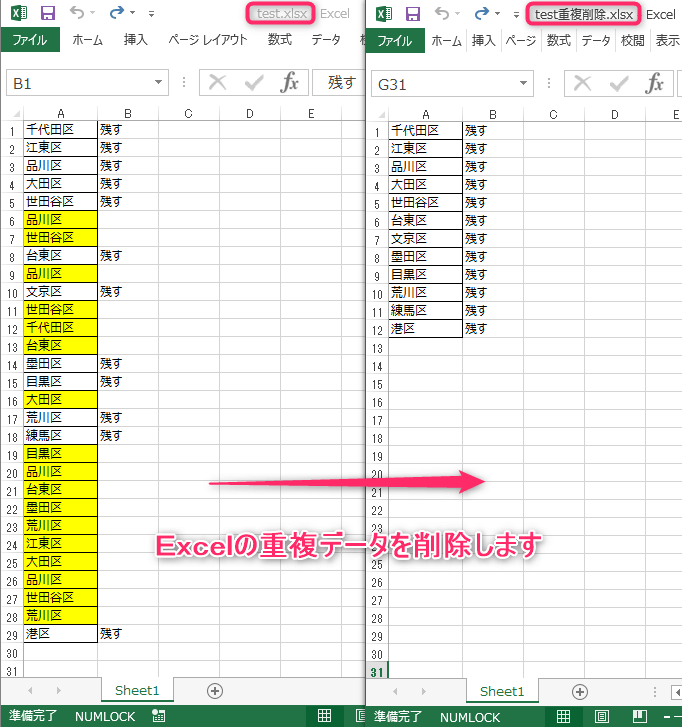
コード実行後
エクセルシート内のデータをチェックして、重複のみ削除します。
下図は結果がわかりやすいように、コード実行前に以下の手作業をしています。
・削除するデータは、背景色を黄色に着色
・削除しないデータは、B列に「残す」と入力
Excelの重複しないデータ抽出
以下のコードを実行すると、重複のないデータを取得します。
import openpyxl
wb = openpyxl.load_workbook('C:/Users/xxx/Desktop/test/test.xlsx')
ws = wb['Sheet1']
#配列宣言
Chiiki = []
i = 0
#A列をループ
for row in ws.iter_rows():
j = 0
for cell in row:
if cell.col_idx == 1:
i = i + 1
#1個目は強制的に配列へ格納
if i == 1:
Chiiki.append(cell.value)
else:
#リストをループ
for list in Chiiki:
#セル値がすでにリストに含まれていたら何もしない
if list == cell.value:
j = j + 1
continue
if j == 0:
#セル値がリストに含まれていなければ配列へ追加
if cell.value is not None:
Chiiki.append(cell.value)
#A列以外はループしない
else:
break
print(Chiiki)
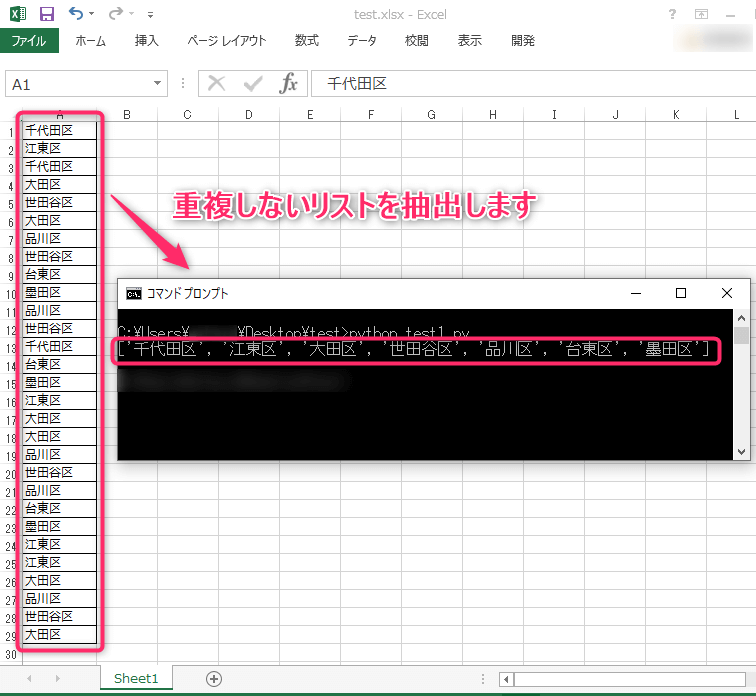
コード実行後
エクセルシート内の重複しないデータを抽出します。
Excelの重複データに色付け
以下のコードを実行すると、エクセルシート内の重複している値に色付けします。
import openpyxl
from openpyxl.styles import PatternFill
wb = openpyxl.load_workbook('C:/Users/xxx/Desktop/test/test.xlsx')
ws = wb['Sheet1']
#配列宣言
My_Value = []
Result_Fruit = []
#セルをループして、値を配列へ格納
for row in ws.iter_rows():
for cell in row:
My_Value.append(cell.value)
#重複データのみ配列に格納
for list in My_Value:
i = 0
for row in ws.iter_rows():
for cell in row:
if list == str(cell.value):
i = i + 1
if i >=2:
Result_Fruit.append(list)
#重複データに色付け
for list in Result_Fruit:
for row in ws.iter_rows():
for cell in row:
if list == str(cell.value):
cell.fill = PatternFill(fgColor='FFFF00',bgColor="FFFF00", fill_type = "solid")
#別名で保存
wb.save('C:/Users/xxx/Desktop/test/test重複色付け.xlsx')
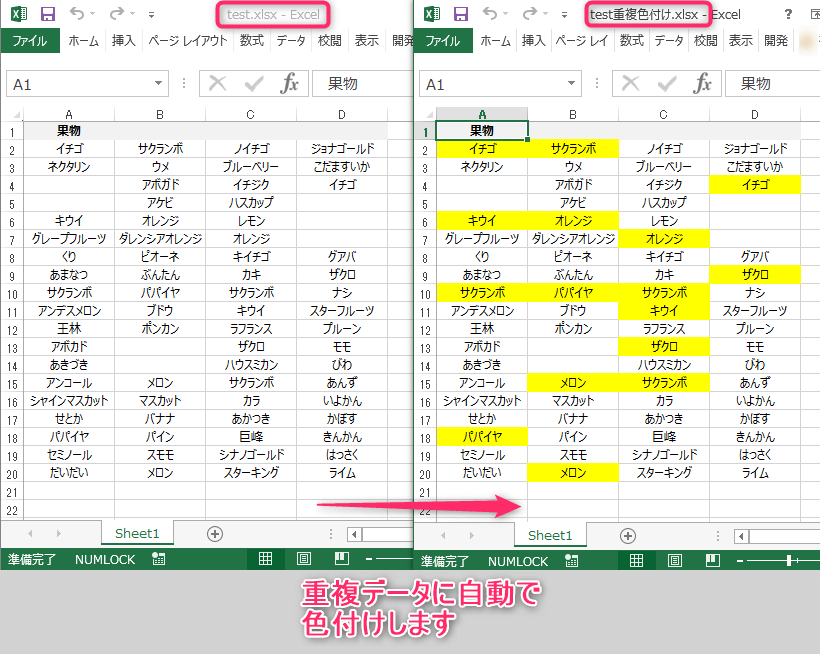
コード実行後
エクセルシート内の重複データに一括で色付けして強調します。
この記事がお役に立ちますと幸いです。
・【Python】エクセルを自動処理する方法まとめ

【Python】エクセル処理を自動化:超便利55選
Pythonで、Excel処理を自動化するコードをご紹介します。ぜひお試しください!
kirinote.com
2022.11.05
「PythonでExcel、メール、Webを自動化する本」
準備に時間をかけず、すぐ始められます
実践的な例題で、実務で本当に使えるプログラムを紹介
自分の仕事を効率化したい方の大きな武器になるオススメの1冊です!
リンク