
PythonのSubprocessを使用して、PDFの一部を画像保存するコードをご紹介します。
ぜひ、お試しください。
PDFを座標指定して画像保存(特定PDF)
以下のコードを実行すると、PDFの一部を画像保存します。
import pyautogui as pag
from PIL import Image
import subprocess
import time
acr_path = "C:/Program Files/Adobe/Acrobat DC/Acrobat/Acrobat.exe"
#PDF指定
pdf_path = 'C:/Users/admin/Desktop/test/PDFファイル/経費精算書_001.pdf'
#PDFファイルを開く
pdf_pro = subprocess.Popen([acr_path,pdf_path],shell=False)
time.sleep(2)
#座標指定箇所を切り取りして画像保存
name_img = pag.screenshot('temp.png',region=(519, 236, 150, 40))
pdf_pro.kill()
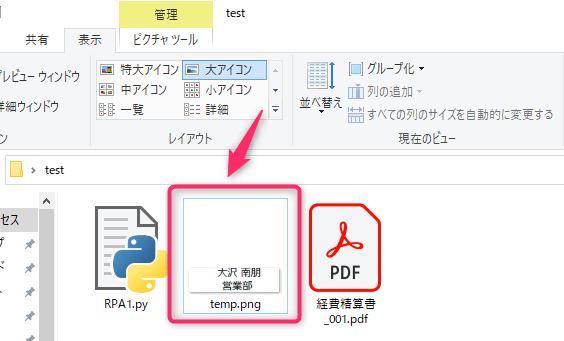
コード実行前
切り抜く部分の座標をあらかじめ取得しておき、
[region=(519, 236, 150, 40)] へ入力します。

コード実行後
指定したPDFファイルを開き、
座標部分を「temp.png」というファイル名で画像保存します。
その後、PDFを閉じます。
PDFを座標指定して画像保存(複数PDF)
以下のコードを実行すると、複数PDFファイルの指定箇所を画像データとして保存します。
import pyautogui as pag
from PIL import Image
import subprocess
import os
import time
acr_path = "C:/Program Files/Adobe/Acrobat DC/Acrobat/Acrobat.exe"
#PDF指定
pdf_path = 'C:/Users/admin/Desktop/test/PDFファイル/'
pdf_list = os.listdir(pdf_path)
i = 1
#フォルダ内にあるPDFファイルをループ
for idx,file in enumerate(pdf_list):
#PDFファイルを開く
pdf_pro = subprocess.Popen([acr_path,pdf_path+file],shell=False)
time.sleep(2)
#座標指定箇所を切り取りして画像保存
name_img = pag.screenshot(str(i) + 'temp.png',region=(519, 236, 150, 40))
i = i + 1
pdf_pro.kill()
time.sleep(1)
コード実行前
[pdf_path] フォルダ内に、複数のPDFファイルが存在しています。
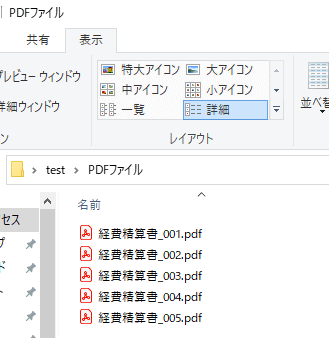
PDFは全ファイル同じフォーマットです。
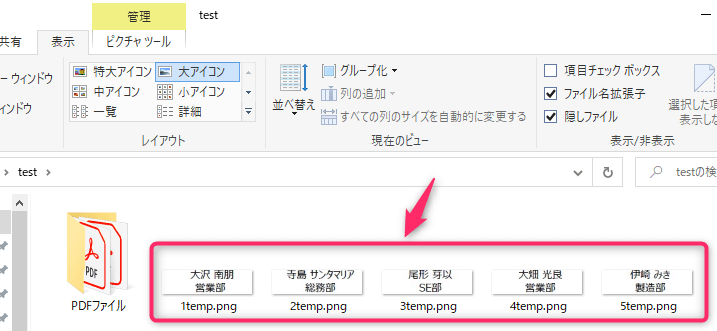
コード実行後
[pdf_path] 内をループし、1つずつPDFファイルを開いて画像を保存します。
指定座標のテキスト部分を抽出することができました。
動作環境
Python 3.7.4
PyAutoGUI 0.9.52
この記事がお役に立ちますと幸いです。

PythonでOCR:PDFから文字抽出(テキスト変換) 動画あり
PythonでPDFの指定範囲(座標)から文字抽出をする方法をご紹介します。動画で動作確認ができます👇pythonでPDFから文字抽出以下のコードを実行すると、PDFを範囲指定して文字認識をします。import pyautogui as p...
kirinote.com
2026.01.02
「Python2年生 スクレイピングのしくみ」
機械学習を始めたい方必見
必要最低限の文法をピックアップして解説
ネットからデータ収集を始めたい方へオススメの1冊です!
リンク