
Power Automate Desktopで、PDFを読み取って画像・テキスト抽出する方法をご紹介します。
ぜひ、お試しください!
PDFから画像を抽出する方法
PDFファイルの中に、5つの画像があります。
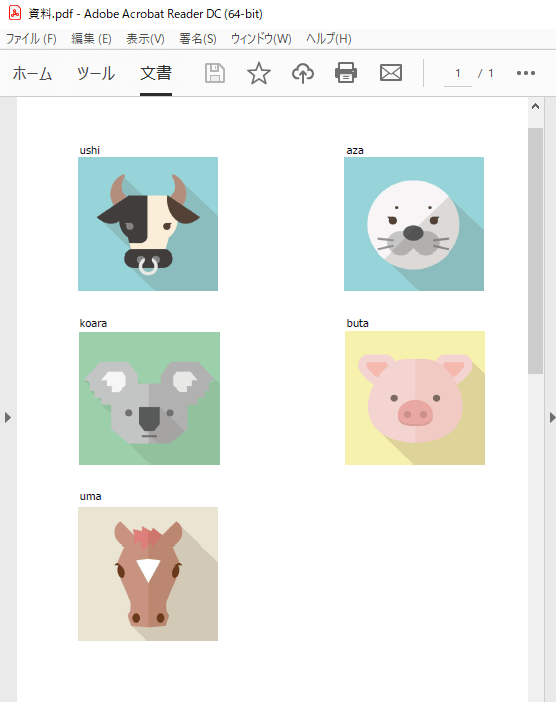
フローは、たった1行です!

「PDFから画像を抽出します」
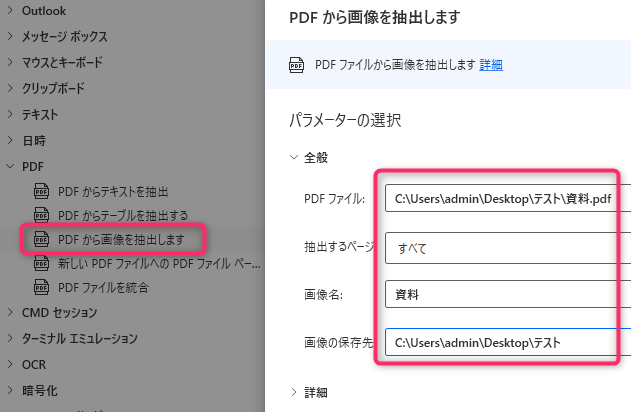
PDFファイルからすべての画像を抜き出して、
pngファイルで保存します。

PDFからテキストを抽出する方法
フォルダに複数のPDFがあります。
PDFは全て同じフォーマットです。
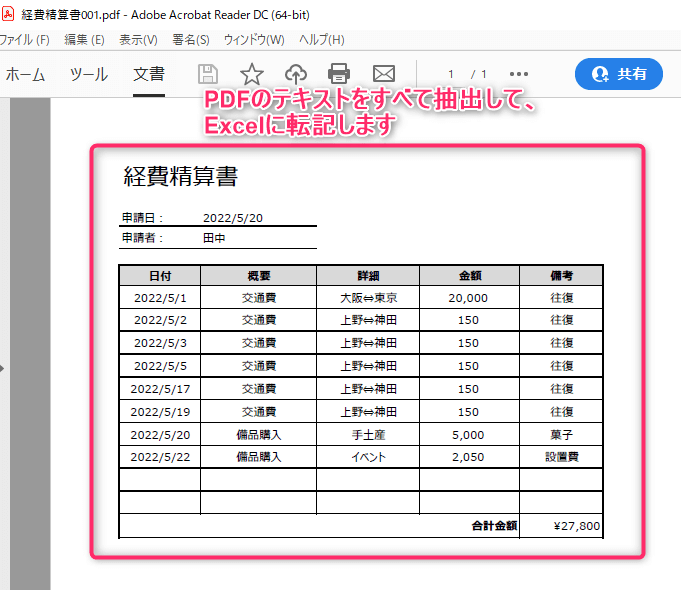
PDFファイルから文字を読み取り、Excelに転記します。
フロー作成で、作り方を詳しく解説します。
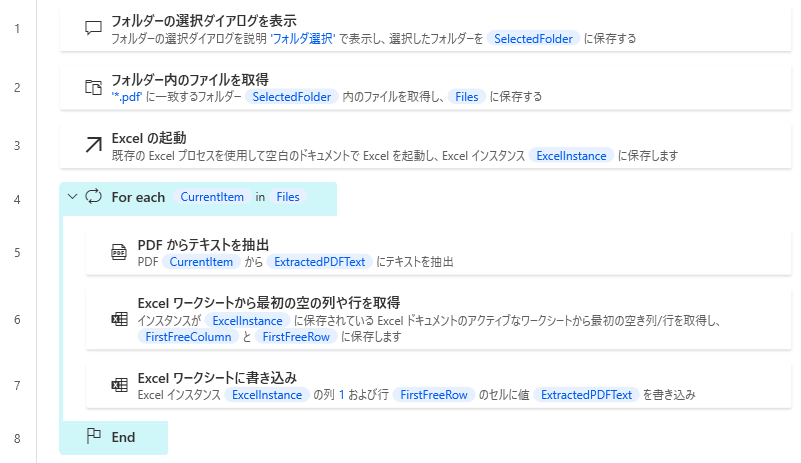
1. 「フォルダーの選択ダイアログを表示」
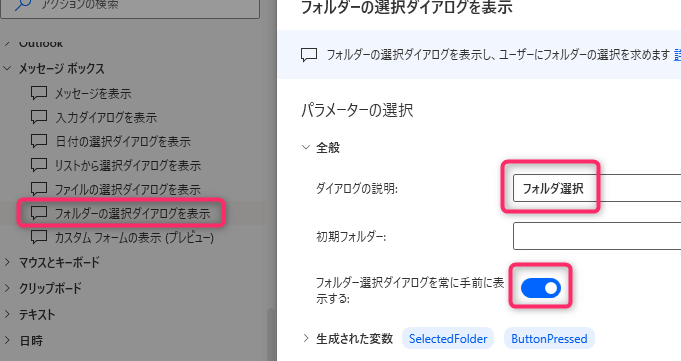
2. 「フォルダー内のファイルを取得」
※「ファイルフィルター」で「*.pdf」と入力し、
PDFファイルのみを対象とします。
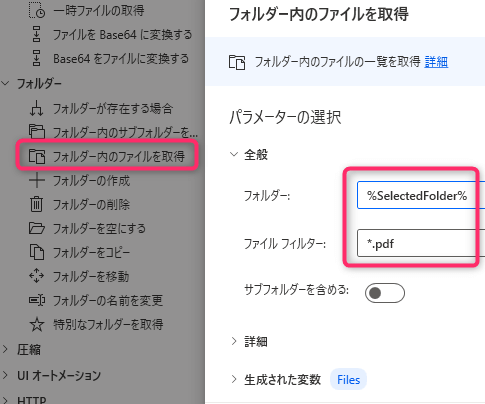
3. 「Excelの起動」
新規ファイルを作成します。
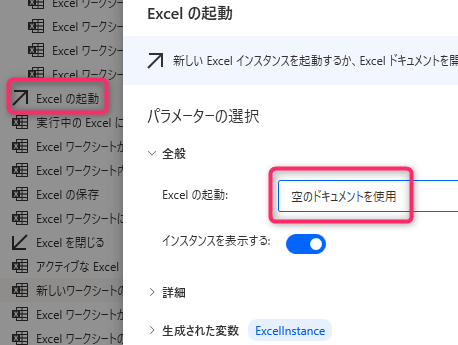
4. 「For each」
フォルダ内にあるPDFファイルをループします。

5. 「PDFからテキスト抽出」
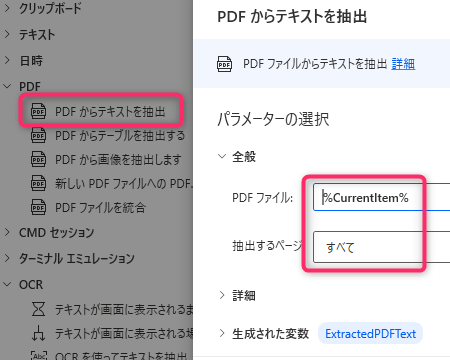
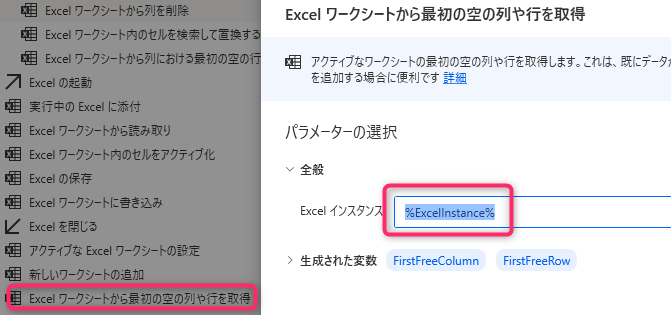
6. 「Excelワークシートから最初の空の列や行を取得」
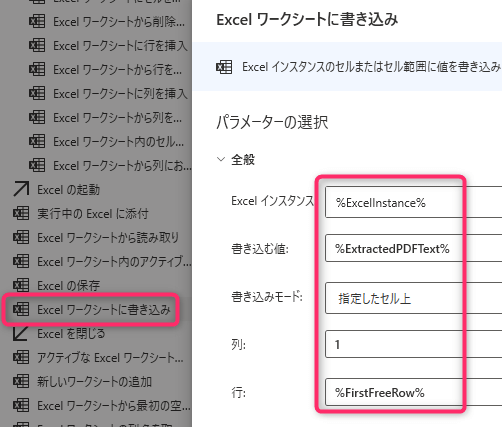
7. 「Excelワークシートに書き込み」
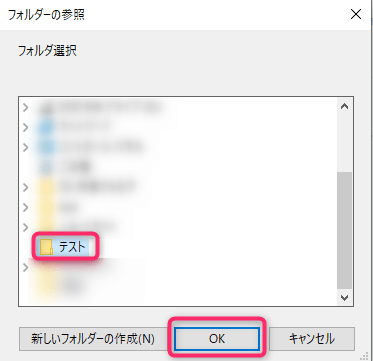
「フォルダーの参照」が表示されるので、対象フォルダを選択する
PDFの文字列をExcelに書き込みできました。
手作業で、行列の幅を調整します。
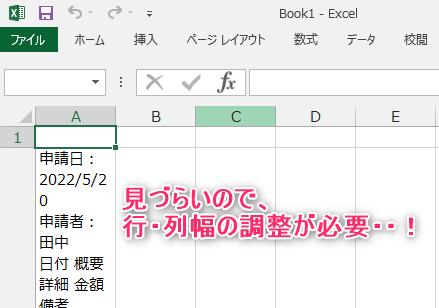
複数PDFのすべての文字を、一括で転記することができました。
見た感じ、1文字残らず取得できています。PADすごい・・!

以上、Power Automate Desktopの活用術でした。
この記事がお役に立ちますと幸いです。

「シゴトがはかどる Power Automate Desktopの教科書」
業務自動化ツールの初心者でも使えるように、初歩から丁寧に解説
繰り返し発生する作業を本書で自動化して仕事を効率化しましょう!!